Reasoning about Regular Properties: A Comparative Study
Abstract. Several new algorithms for deciding emptiness of Boolean combinations of regular languages and of languages of alternating automata have been proposed recently, especially in the context of analysing regular expressions and in string constraint solving. The new algorithms demonstrated a significant potential, but they have never been systematically compared, neither among each other nor with the state-of-the art implementations of existing (non)deterministic automata-based methods. In this paper, we provide such comparison as well as an overview of the existing algorithms and their implementations. We collect a diverse benchmark mostly originating in or related to practical problems from string constraint solving, analysing LTL properties, and regular model checking, and evaluate collected implementations on it. The results reveal the best tools and hint on what the best algorithms and implementation techniques are. Roughly, although some advanced algorithms are fast, such as antichain algorithms and reductions to IC3/PDR, they are not as overwhelmingly dominant as sometimes presented and there is no clear winner. The simplest NFA-based technology may sometimes be a better choice, depending on the problem source and the implementation style. We believe that our findings are relevant for development of automata techniques as well as for related fields such as string constraint solving.
Updates and News
- 4.5.2023: Our paper has been accepted to CADE'23
Links to resources
- arXiv preprint: preprint of our paper.
- For more recent version of our paper, either check the official CADE'23 submission or newer version in the arXiv.
- Replication Package: A virtual machine for replication of our results
- The replication package is in
.ovaformat and needs to be imported in some virtual image manager (see, e.g., VirtualBox or VMware). - The replication packages occupies about 10GB of data.
- The package contain detailed instructions, how to replicate our results in README.md
- Benchmarks: source benchmarks that were used in the comparison.
- Read README.md for more details.
- Results: results measured and used in the comparison.
-
This contains source data files with measured times for listed tools and benchmarks (in
csv), and also replication script in form of jupyter notebook that generates figures used in paper. - Benchmarks (mirror): mirror of source benchmarks that were used in the comparison.
- Cloning our benchmarks from this mirror requires
git-lfssupport (see https://git-lfs.com/) - Note that the benchmarks are quite extensive and occupies more than 10GB of storage.
Summary of Tools and Benchmarks
In following we provide brief list of used benchmarks and tools. For full description, either see the paper, the replication package or our benchmark repository.Tools
bwIC3is our own implementation of backward reduction based on the model checker ABC.Bisimis an Java implementation of the AFA-emptiness check based on bisimulation.Bricksis a baseline automata library primarly focusing on DFA; available at dk.brics.automaton.CVC5is an automatic theorem prover for SMT; available at cvc5Automatais a C# library implementing symbolic NFA/DFA; available at Automata.JAltImpactis an implementation of interpolation-based algorithm; available at: JAltImpact.AntiSatis our own implementation of antichain AFA emptiness test integrated with SAT solver.Monais an optimized implementation of DFA; available at The Mona project.eNFAis our own implementation of NFA.VATAis a library implementing NFA; available at libvata.Z3is an automatic theorem prover for SMT developed by MicroSoft; available at Z3.
Boolean combinations of regular expressions benchmark.
This group of BRE contains benchmarks on which we can run all tools, including those based on NFA and DFA. They have small to moderate numbers of minterms (about 30 in average, at most over a hundred).-
b-smtcontains 330 string constraints from the Norn and SyGuS-qgen, collected in SMT-LIB benchmark [8], that fall in BRE. -
b-hand-madehas 56 difficult handwritten problems from [73] containing membership in regular expressions extended with intersection and complement. They encode (1) date and password problems, (2) problems where Boolean operations interact with concatenation and iteration, and (3) problems with exponential determinization. -
b-armc-inclcontains 171 language inclusion problems from runs of abstract regular model checking tools (verification of the bakery algorithm, bubble sort, and a producer- consumer system) of [12]. -
b-regexcontains 500 problems, obtained analogously as in [30] and [77], from RegExLib [71]. -
b-paramhas 8 parametric problems. Four are from [40]. Another four are from [28].
AFA Benchmark
The second group of examples contains AFA not easily convertible to BRE. Here we can run only tools that handle general AFA emptiness. Some of these benchmarks also have large sets of minterms (easily reaching to thousands) and complex formulae in the AFA transition function, hence converting them to restricted forms such such as separated DNF or explicit may be very costly.-
a-ltlf-patternscomes from transformation of linear temporal logic formulae over finite traces (LTLf) to AFA [34]. The 1699 formulae are from [60]8 and they represent common LTLf patterns which can be divided into two groups: (1) 7 parametric patterns (100 each) and (2) randomly generated conjunctions of simpler LTLf patterns (999 formulae). -
a-ltl-randcontains 300 LTLf formulae obtained with the random generator of [77]. The generator traverses the syntactic tree of the LTL grammar, and is controlled by the number of variables, probabilities of connectives, maximum depth, and average depth.We have set the parameters empirically in a way likely to generate examples difficult for the compared solvers (the formulae have 6 atomic propositions and maximum depth 16). -
a-ltl-paramhas a pair of hand-made parametric LTLf formulae (160 formulae each) used in [30] and [77]: Lift [43] describes a simple lift operating on a parametric number of floors and Counter [72] describes a counter incremented modulo the parameter. -
a-ltlf-spec[60] contains 62 LTLf formulae that specify realistic systems, used by Boeing [14] and NASA [42]. The formulae represent specifications used for designing Boeing AIR 6110 wheel-braking system and for designing NASA NextGen air traffic control (ATC) system. -
a-sloth4062 AFA emptiness problems to which the string solver Sloth reduced string constraints [47]. The AFA have complex multi-track transitions encoding Boolean operations and transductions, and a special kind of synchronization of traces requiring complex initial and final conditions. -
a-noodler13840 AFA emptiness problems that correspond to certain sub-problems solved within the string solver Noodler in [10]. The AFA were created similarly as those ofa-sloth, but encode a different particular set of operations over different input automata.
Key results
In the following, we list our key results summarized in tables and figures. For bigger vector version of the images, click on the image preview.Summary of benchmarks
Summary of AFA and BRE benchmarks. Table lists (i) the average, (ii) the median, and (iii) the number of timeouts and errors (in brackets). Winners are highlighted in bold.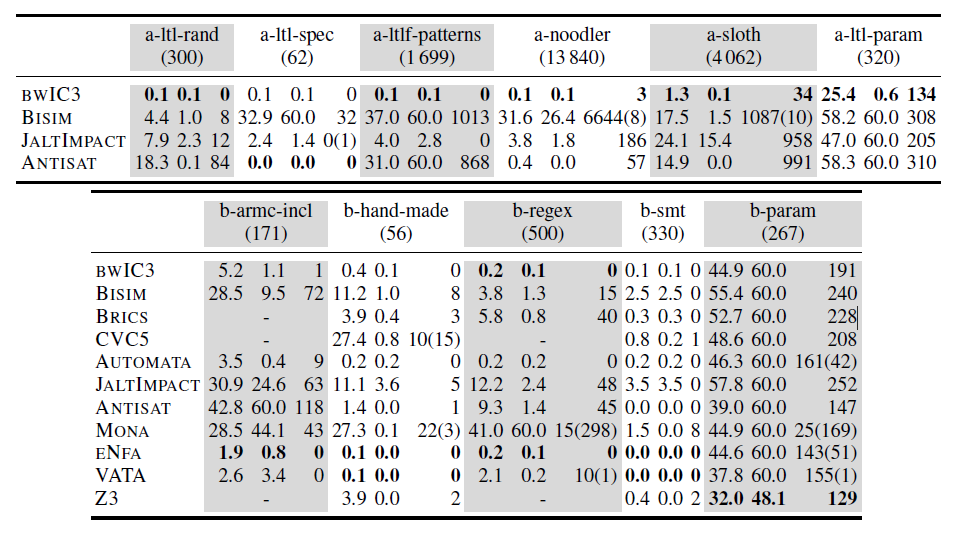
Cummulative runtime on benchmarks
Cactus plots of AFA and BRE benchmarks. The y axis is the cumulative time taken on the benchmark in logarithmic scale, benchmark on the x axis are ordered by the runtime of each tool.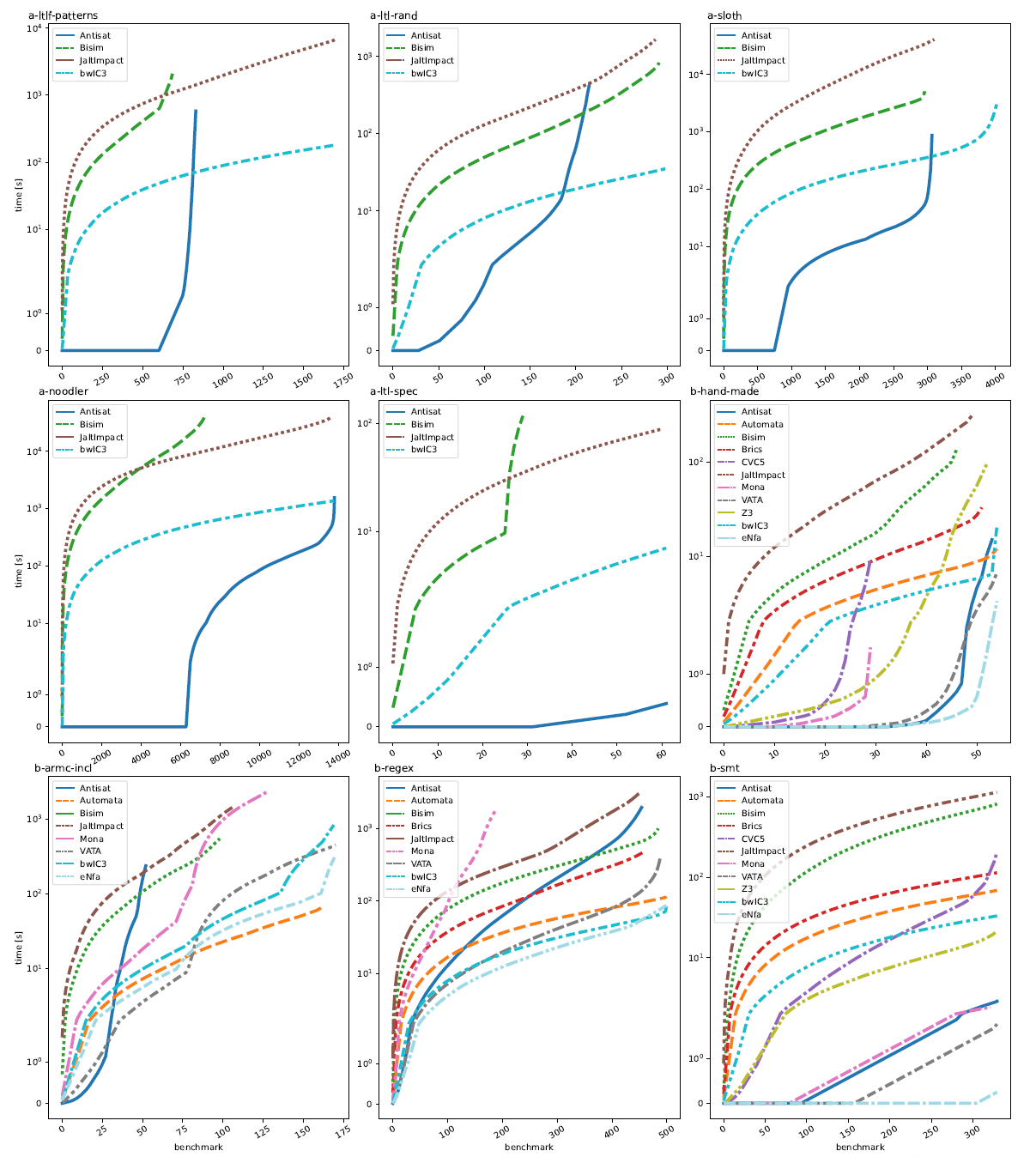
Runtime on parametric benchmarks
Models of runtime on parametric benchmarks based on specific parameter k with timeout 60s. The sawtooths represent the tool failed on the benchmark for some k while solving benchmarks for k-1 and k+1. For brevity, we draw the models only until they start continually failing.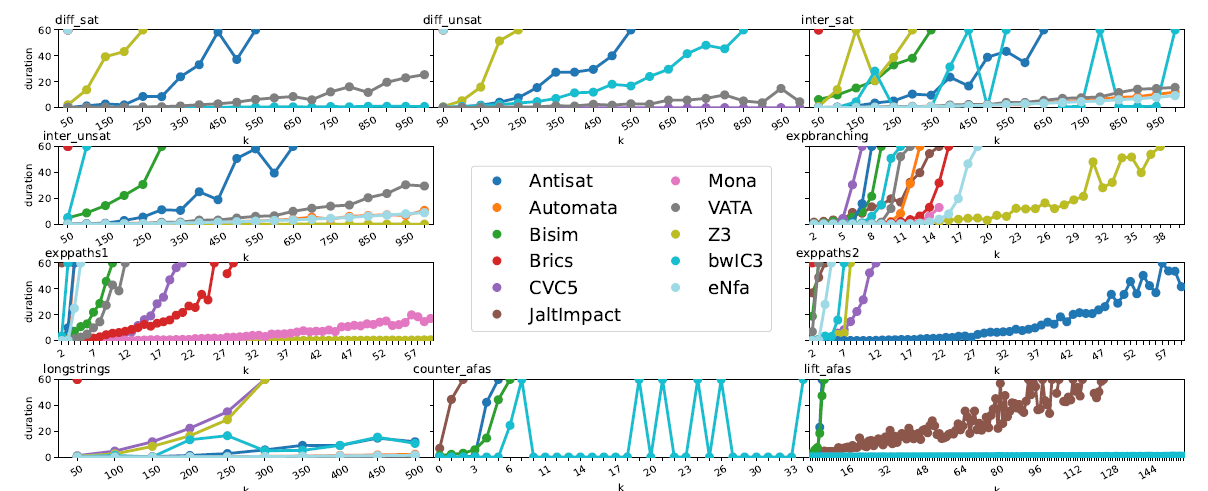
Contributing
We encourage researchers and practitioners to actively contribute to our ongoing efforts by expanding our results through the addition of new benchmarks, new tools and by engaging with our open-source repositories. By introducing new benchmarks that encompass a wider range of scenarios and challenges, we can collectively advance the field and provide more comprehensive evaluations of various tools and techniques. Our repositories are open for forking, enabling interested individuals to explore, modify, and build upon our codebase. If you are interested in contributing your own benchmark, we suggest following:
-
Fork our benchchmark repository.
Add your own benchmark in
.mata(see definition of.mataformat) or.afaformat. - Create a Pull Request from your fork. We will check your contribution, optionally request changes and if we are satisfied, we will merge the changes into our repository.
- Note that we will try our best to include your benchmarks into our experiments, but we cannot assure we will have enough time / resources to do so. So please be considerate.
- Sends us repository, with clear instructions how to compile and run your tool
- Since, our environment is in form of virtual machine, you can potentially send us the whole machine, however, we prefer, to check and run your tool ourselves (this might give you additional feedback to your tool as well).
- We will process the results.
-
Note that, we might try to create some better way of integrating the tools and distributing
the environment (e.g., through
dockerfileor some other alternative). However, we believe, virtual machine is sufficient.
Limitations and Future work
Threats to validity. Our results must be taken with a grain of salt as the experiment contains an inherent room for error. Although we tried to be as fair as possible, not knowing every tool intimately, the conversions between formats and kinds of automata, discussed at the start of Section 5, might have introduced biases into the experiment. Tools are written in different languages and some have parameters which we might have used in sub-optimal way (we use the tools in their default settings), or, in the case of libraries, we could have used a sub-optimal combination of functions. We also did not measure memory peaks, which could be especially interesting e.g. in when the tools are deployed on a cloud. We are, however, confident that our main conclusions are well justified and the experiment gives a good overall picture. The entire experiment is available for anyone to challenge or improve upon.Currently, we work on the following extensions of our experimental evaluation:
- Enhancing our benchmarks and environment: Our current setup is still rather a prototype with lots of obsolete code, steps and scripts. We wish to enhance the virtual machine, the benchmark repository as well as results repository to better shape.
-
Enhancing the precision of the results: We mentioned above some of the threats to validity
of our results. We wish to enhance the precision and our own trust in the results. We think we
might have been unfair to some tools, and, moreover, we are quite surprised by some results
(e.g., we expected the implementation of the AFA-emptiness implementations of work of
[D'Antoni18] implemented in tool that we refer
to as
Bisimto be faster). We wish to explore other parameters of the tools, as well as enhancing the results by measuring in higher level of granularity (i.e., including how much parsing, preprocessing steps or conversion between formats take). - Comparing tools based on other metrics: We compared the tools based on the runtime only. We believe, that comparing the tools, e.g., regarding the memory peak (i.e., the maximal amount of allocated memory) might provide additional insight and could be useful to those that wish to apply these tools and approaches in practice (e.g., in cloud or their own server).
Contact Us
- Tomas Fiedor <ifiedortom@fit.vutbr.cz>
- Lukas Holik <holik@fit.vutbr.cz>
- Martin Hruska <ihruska@fit.vutbr.cz>
- Adam Rogalewicz <rogalew@fit.vutbr.cz>
- Juraj Sic <sicjuraj@fit.vutbr.cz>
- Pavol Vargovcik <ivargovcik@fit.vutbr.cz>
Acknowledgements
This work has been supported by the Czech Ministry of Education, Youth and Sports ERC.CZ project LL1908, and the FIT BUT internal project FIT-S-20-6427.